Recently I came across this article at the CommLab India blog which presents an interesting opinion on measuring the training effectiveness using the Kirkpatrick model (diagram shown below). The author conjectures that the only practical way to measure this in practice is through Level 2 assessment (i.e., “testing” the student’s retained knowledge). Level 3 and Level 4 (degree of application of concepts and achievement of training objectives, respectively) are unreliable, the writer argues, since these types of measurements don’t exclude external factors, and thus make it difficult to attribute enhanced performance exclusively to training activities.
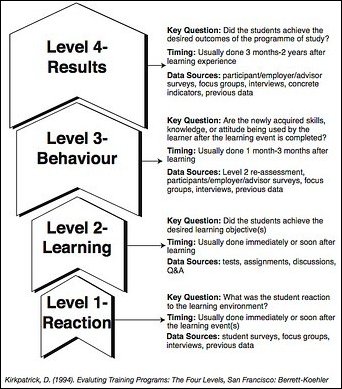
Thinking this through, I can see where the author is coming from… the only way to TRULY know if training has enhanced performance with 100% certainty at Level 3 would be to control for all other variables in experimental conditions. Even worse at Level 4 – in the real world the “targeted outcomes” of training are rarely realistic, and usually dictated by managers with no concept of how things work at the front line. If the “targeted outcome” of a course is to teach calculus to a group of monkeys, failure is all but guaranteed unless you have some highly motivated and intelligent monkeys. But I digress.
{kind=link}
While the author has some compelling points in theory, life is not always so simple. In fact, I would argue that as a trainer, focusing on Level 2 results as a measure of training quality is myopic at best, and career suicide at worst. And here’s why:
We can’t always control everything. In the best case, you design training which you then deliver in a controlled setting, where you are able to proctor students during the Level 2 assessment, and then follow that up with on-the-job coaching. In the situations I typically deal with, however, things are different. You design training materials for technical topics, which are then delivered to students thousands of miles away by non-technical trainers provided by a 3rd party who have received one to two hours of coaching on delivery of the material. These trainers then proctor the students during Level 2 assessment. Of course, the 3rd-party trainer has a vested interest in student performance (was it their fault all the students flunked?), and therefore it’s not rare to see perfect assessment scores from 90-95% of the trainees. This is a red flag. How can we trust those results when we KNOW students are being coached through the assessments? (In my particular situation, we confirmed this when we “planted” questions that would be scored correct given the wrong answer… and still saw 95% perfect scores.)
Second, consider the question: why does a business deliver training to its employees? Productivity, efficiency, performance. Increased output from the same inputs. If this is the goal, does it really make sense to measure training effectiveness using any metrics other than employee performance? From a manager’s perspective, a Level 2 assessment offers no information to justify the existence of a training program – how do you measure ROI with test results? From a trainer’s perspective – how do you prove your value and justify your existence with Level 2 results if students fail to improve at Level 3?
So what can we learn from this? I think the main point for the instructional designer is never lose sight of your ultimate goal – enhanced employee performance – because ultimately, it’s the only good way to show a return on a training investment, as well as one of the only ways to justify your existence within an organization. For the manager, the main lesson is that training effectiveness relies not just on excellent materials and delivery, but also on establishing realistic objectives and supplementing training with reinforcing activities like hands-on practice and on-the-job coaching.
1 reply on “Oh, Dr. Kirkpatrick! Measuring Training Outcomes In An Imperfect World”
[…] again readers! Last time we “met,” I had the pleasure of walking you through a quick primer on the Kirkpatrick model and how to best use it to assess the effectiveness of a given training program or set of training […]